

[admonition title="授权声明" icon="info" color="indigo"]感谢 @無音零 提供本次测试训练集(图片)。没有她的慷慨协助,本次测试将无从开展。
本次测试过程中使用的数据集及生成的 Hypernetwork,将在所有测试完成后彻底删除。[/admonition]
前言
在 AI 绘画进入大众视野中时,其技术的更新迭代引起了人们的广泛关注,也掀起了一股“ AI 热”。
但是,自其面世以来,AI 学习本身也引来了不少的争议:训练所用的数据集,大多没有经过其原创作者的授权;AI 训练这个过程的版权归属目前也难以界定。
况且还有很大一部分艺术工作者本身就不希望其作品被用于 AI 学习。
在 AI 深度学习的发展与争议下,Glaze 这个软件应运而生:它通过一些特定的算法,在图像上生成了一定的扰动,声称可以干扰不少主流的深度学习。这可以使创作者在对外公布作品时免受非授权学习的担忧。
从该软件的初衷看,它无异于给广大艺术创作者对其作品被 AI 学习说“不”的权力,也是对抗目前版权模糊难以界定而生的强力保护。但是,它的实际效果又是如何呢?
测试环境
本次测试数据集来源于 @無音零 的绘画作品,再次感谢!
本次测试的环境为:
- 阿里云 机器学习 PAI - DSW
- Intel(R) Xeon(R) Platinum 8369B CPU @ 2.90GHz x8
- 30 GB RAM
- NVIDIA A10 GPU
- Ubuntu 22.04 + CUDA 11.7 + PyTorch 1.13
Sun Apr 23 15:42:41 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 470.103.01 Driver Version: 470.103.01 CUDA Version: 11.7 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA A10 On | 00000000:00:07.0 Off | 0 |
| 0% 61C P0 149W / 150W | 7769MiB / 22731MiB | 97% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
本次测试将在 Stable Diffusion Webui 中进行。测试未在最严格的情况下进行,结果仅供参考。
图像预处理
经过画师允许,博主从其 Pixiv 账户下爬取了所有的插画。
经过初步筛选(去除差分图,去除带签名/文字图片,去除部分影响结果图片)后,大概获得了 43 张原图进行处理。
生成实验组(干扰图像)
我们先对已经获取的原图,在 Glaze 软件中进行处理。
要注意,首次打开 Glaze 时,会在用户目录下下载大约 4GB 的依赖库,下载耗时较长。若有需要卸载也请在对应目录下(官方网站有指引),将依赖库删除。
使用此软件,你需要有一张显存 >= 4GB 的 NVIDIA 显卡,并已经安装了 CUDA。
受限于软件,每次只能处理 20 张图片,本次测试需要分三次处理。
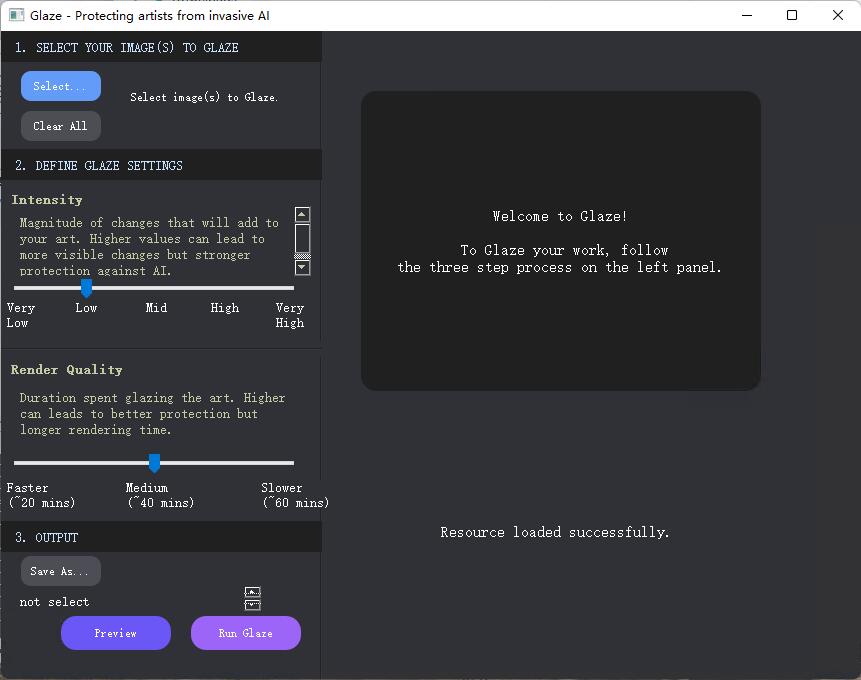
我们将 Intensity 设置到 Mid ( 50 ),Render Quality 设置到 Medium ( 2 ),对所有图像进行处理。
图像处理前后的对比如下:

可见,该软件对图像产生了细微可见的干扰,图片有一定的类似“釉”(或者说油层)的质感。
至此,生成了我们本次测试的实验组。
图像预处理
未经过处理的原图和干扰实验组并不能直接用于训练,我们需要在 Stable Diffusion 中先进行预处理。
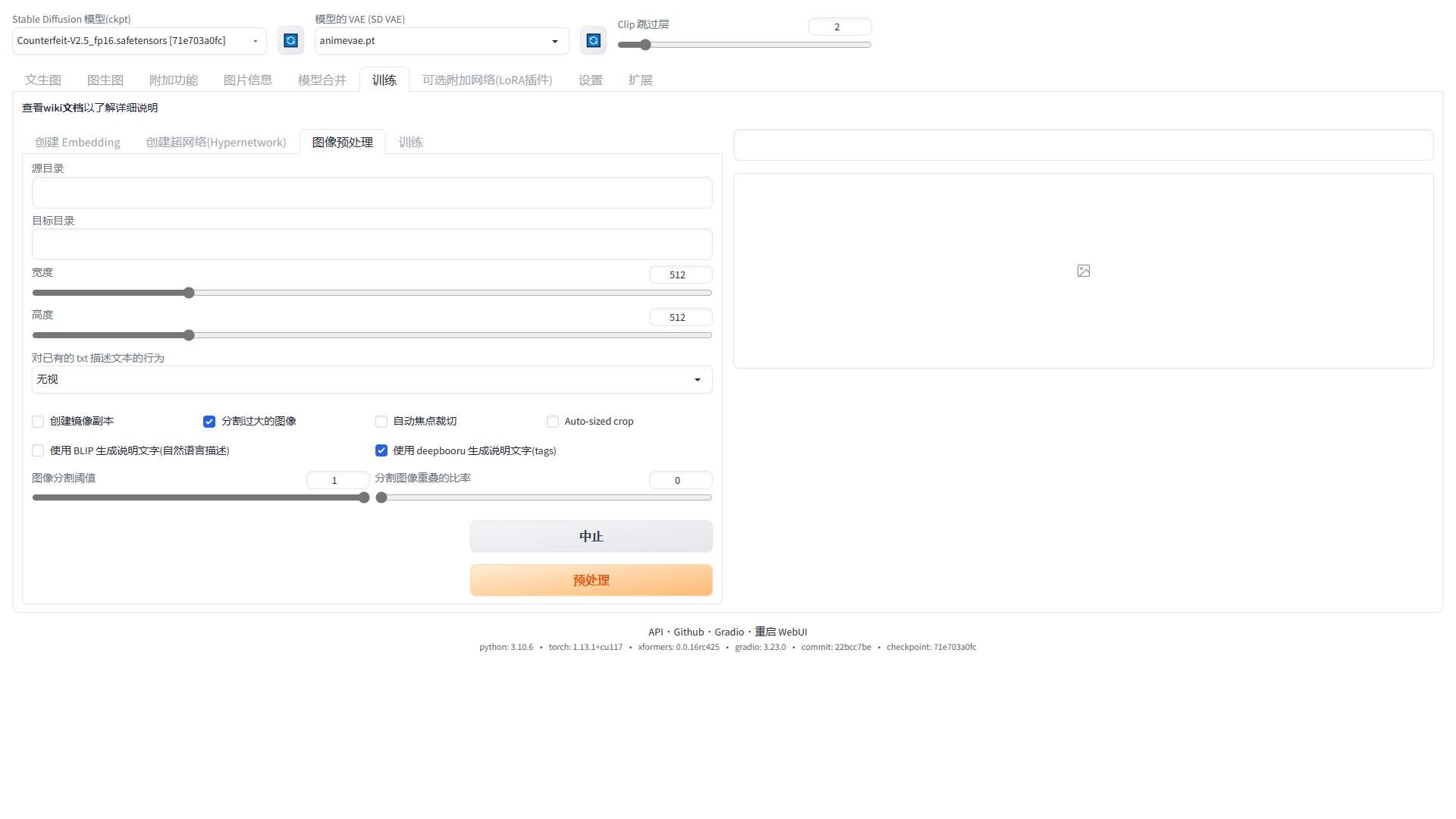
如图所示,我们进入训练-图像预处理,设置图片的源目录(存储原图)和目标目录(输出训练集)。
在这里,我们选择分割过大的图像,将阈值拉到1,重叠比率拉到0。在这种情况下,可以对一张过大的图片分切出两个部分(视其宽高决定),能够获得更多的可用数据集。
然后使用 deepbooru 生成说明文字。这样可以全自动给图片打 tag,避免人工添加描述的麻烦。
生成完成后,我们能在对应的目标目录中看到被分割为 512 x 512 大小的图片,及其对应的描述 tag 文本。
对原图和干扰实验组都进行同样的操作,存入不同的目录中。
超网络训练
完成了预处理后,我们分别对两组训练集进行训练。
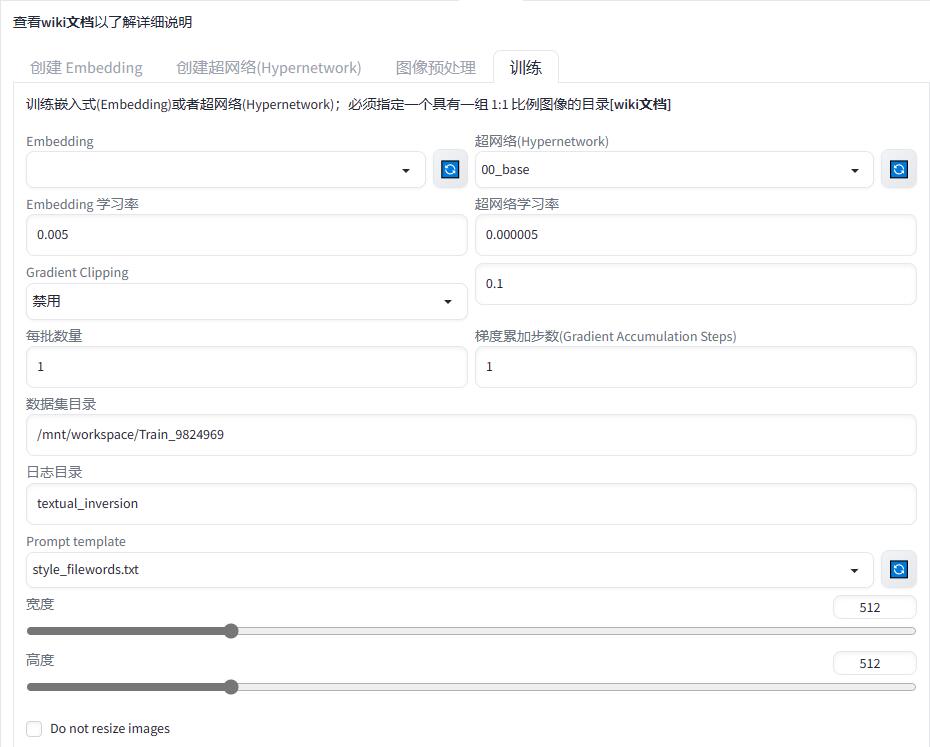
分别定义两个不同名称的 Hypernetwork,其各项参数保持 webui 中的默认值:

创建完成后,进入训练界面。
在这里我们选中对应要训练的 超网络(Hypernetwork),将其学习率设置到 0.000005。
数据集目录设置为我们预处理过的图像对应目录,训练过程中会循环读取其中的图片和 tag 信息。
最大步数设置到 10000-50000 之间(就算跑完了也可以后续追加),其他参数保持默认。
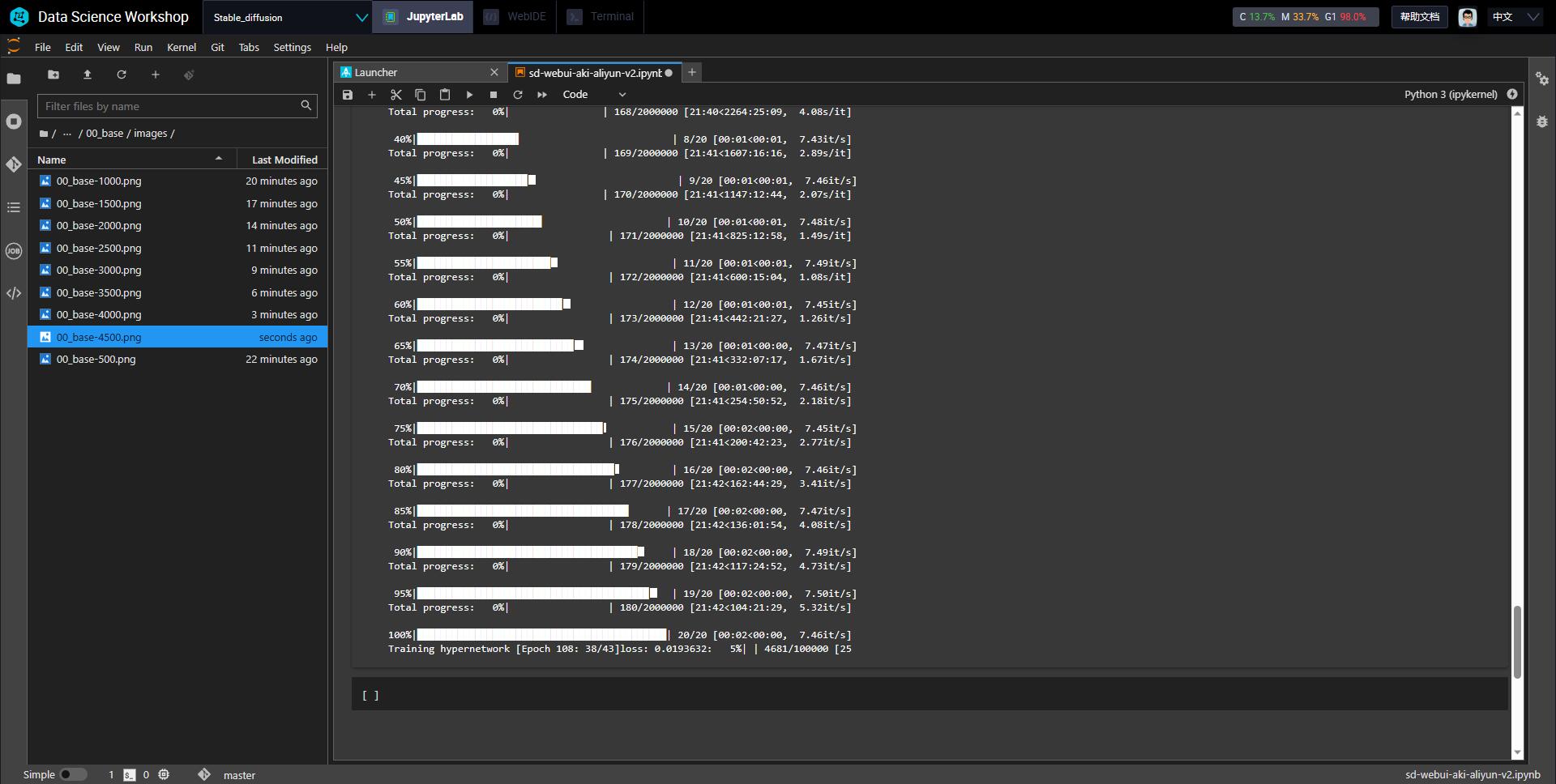
点击训练超网络,即可开始训练,这个过程持续时间较久,博主的使用配置下在一小时 11k steps 左右。
在后台可见程序正在全力学习,并且每 500 steps 会生成一张图片供预览,防止过拟合错失停止训练时机。
测试结果
经过了上述的训练,我们将训练过程中不同steps的超网络保存。
并且在同样的生成参数,同样的prompt和生成种子下,生成图片进行对比。
对比结果如下图所述:

但后续的学习没有过多偏差。

在30000steps时,干扰组甚至产生了更好的效果。
可见的是,Glaze 生成的扰动图像并没有对此次的 Hypernetwork 训练产生任何可见的影响。
所有的训练与生成都能正常进行,也就意味着这种干扰没有产生任何作用。
总结
在本次测试中,Glaze 对于 Hypernetwork 超网络训练的干扰影响甚微,可谓完全没有达到其声称的功能。
对比进行图片处理后可见的细节和观感损失,这种处理在目前而言可谓是失去意义的。
当然,博主希望,在将来有一天, AI 的使用能够更加规范,我们相应也更能以更积极的心态拥抱新技术。
但愿以后,AI 训练的开展,能够得到一个令各行各业所接受的方案,能够在秩序下进行与发展;到那时,也不再需要这样的对抗和矛盾了。
Comments 2 条评论
好厉害的说
前脚1k捡完洋垃圾,后脚就上A10炼丹是吧(笑)
只能说目前的防AI学习手段得不偿失,无论是Glaze还是Mist都效果有限且严重影响观感。而且现在的训练手段只需要非常小的数据集就足够,根本不会缺训练材料,瓶颈早已不在数据质量上而在于细节处理的算法上了。
客观地说AI还有很长的路要走,但不客气地说,AI的出现恰好反映了当今作品的风格单一与同质化严重。身为创作者,确实应当好好思考自己创作的目的究竟是什么,而什么又才是真正的创作。若是一个人以作画作为自我表达的方式而并非虚荣心作祟,那我想,作画这一过程所带来的满足与快乐,是无论AI发展多久都无法取代的。